前面幾篇文章介紹了 GKE Nvidia GPU 的應用,今天將要介紹一個特殊硬體 TPU 的應用。將引導您如何在 Google Kubernetes Engine (GKE) 上使用 TPU 節點部署 Gemma 7B 輕量級大型語言模型,並透過 JetStream 推理服務框架和 Gradio 介面,構建一個高效能的問答系統。
文章涵蓋了設置 TPU GKE 節點池、獲取 Gemma 模型訪問權限、轉換模型檢查點到部署 JetStream 和 Gradio 的完整流程。
我們將利用 TPU v5e 的強大算力,結合 JetStream 的優化策略,最大化 Gemma 模型的性能。
TPU 是 Google 定製開發的應用專用積體電路 (ASIC),用於加速機器學習和使用 TensorFlow、PyTorch 和 JAX 等框架構建的 AI 模型。
主要有兩種 TPU 節點池:
使用 TPU GKE 節點池:
Gemma 是一個由 Google AI 開發的輕量級開源大型語言模型 (LLM) 系列。它有兩個主要版本:2B 參數和 7B 參數的模型,每個版本都包含一個基本預訓練模型和一個指令微調模型。本文示範使用 7B 參數的 Gemma
以下是 Gemma 的一些主要特性:
Gemma 作為一個輕量級、開源且高效能的 LLM,為自然語言處理領域的研究和應用提供了新的選擇,尤其是在資源受限的環境下。隨著模型的進一步發展和社群的貢獻,Gemma 的應用前景將更加廣闊。需要注意的是,儘管 Gemma 支援繁體中文問答,但生成的文本可能包含簡體中文。
JetStream 是由 Google 開發的一款開源推理服務框架。 它專門針對大型語言模型(LLM)的輸送量和記憶體進行了優化,旨在提高開源模型的單位美元性能,並相容 JAX 和 PyTorch/XLA 框架,從而降低成本並提高效率。 JetStream 可以在 TPU上實現高性能。
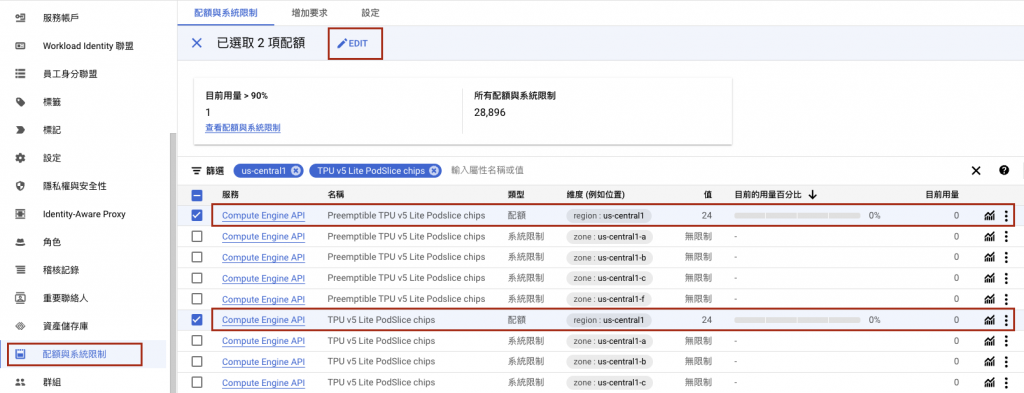
在創建 TPU 機器之前,請先到 IAM > Quota(配額與系統限制) 申請 TPU 的機器數量,篩選列中輸入 TPU v5 Lite Podslice chips,填入 8 以上,根據需求下圖中兩項 Preemptible 和 一般,擇一申請即可,分別代表的是 Spot 機器和 on-demand 機器。
使用 Day3 範例創建的Cluster,再創建一個具有 2x4 拓撲 1 個節點的 TPU v5e x 8 的 Node Pool。
module "gke" {
node_pools = [
var.gemma-7b-tpu.config,
]
node_pools_labels = {
"${var.gemma-7b-tpu.config.name}" = var.gemma-7b-tpu.kubernetes_label
}
node_pools_taints = {
"${var.gemma-7b-tpu.config.name}" = var.gemma-7b-tpu.taints
}
node_pools_resource_labels = {
"${var.gemma-7b-tpu.config.name}" = var.gemma-7b-tpu.node_pools_resource_labels
}
}
variable "gemma-7b-tpu" {
default = {
config = {
name = "gemma-7b-tpu"
machine_type = "ct5lp-hightpu-8t"
node_locations = "us-central1-a"
autoscaling = false
node_count = 1
local_ssd_count = 0
disk_size_gb = 200
spot = true
disk_type = "pd-ssd"
image_type = "COS_CONTAINERD"
enable_gcfs = false
enable_gvnic = false
logging_variant = "DEFAULT"
auto_repair = true
auto_upgrade = true
preemptible = false
}
node_pools_resource_labels = {}
kubernetes_label = {
role = "gemma-7b-tpu"
}
taints = []
}
}
創建出的 TPU Node Pool 會有以下兩個特殊標籤:
如需訪問 Gemma 模型以部署到 GKE,您必須先簽署許可同意協議。
您必須簽署同意協議才能使用 Gemma。 請按照以下說明操作:
如需通過 Kaggle 訪問模型,您需要 Kaggle API 令牌。
如果您還沒有令牌,請按照以下步驟生成新令牌:
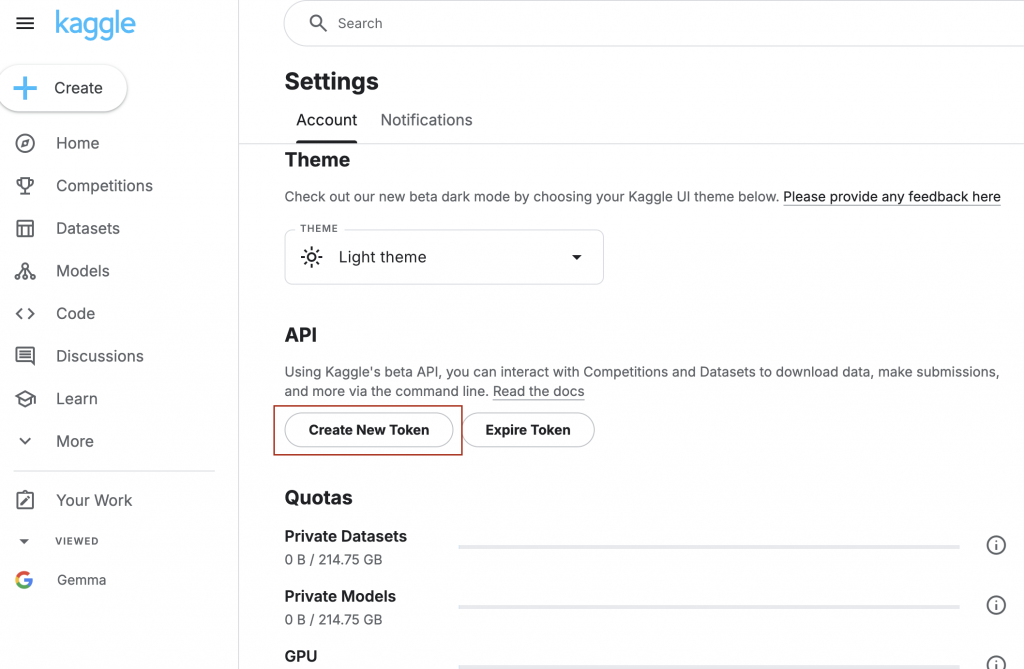
系統將下載名為 kaggle.json 的文件,並使用以下指令將 kaggle.json 保存到 GKE 的 Secret 物件中。
$ kubectl create secret generic kaggle-secret -n ai \
--from-file=kaggle.json
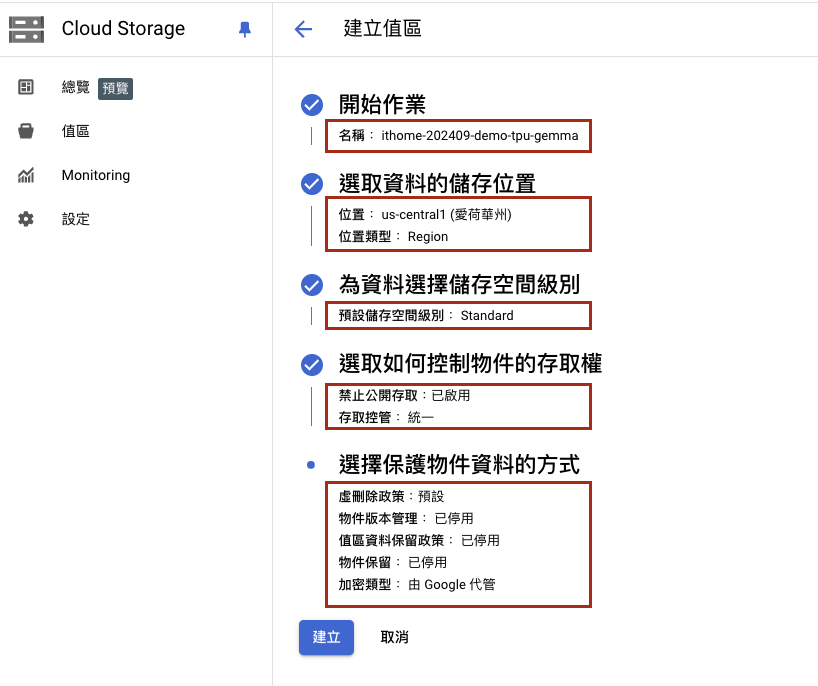
使用 Day6 的教學,在 ai Namespace 下創建 K8s SA demo-ai-cluster-general 使其和 GCP SA demo-ai-cluster-general 綁定,具有 roles/storage.insightsCollectorService 及 roles/storage.objectAdmin的權限,因為筆者有跨專案存取 GCS ,所以將 GCS 所在的專案名稱及權限填在這裡 additional_projects
## Service account
ai = {
gcp_service_account = "demo-ai-cluster-general"
k8s_service_account = "demo-ai-cluster-general"
k8s_service_account_namespace = "ai"
use_existing_gcp_sa = false
use_existing_k8s_sa = false
roles = [],
# 填入管理 GCS 所在的專案
additional_projects = {
"ithome-202409-demo" = [
"roles/storage.insightsCollectorService",
"roles/storage.objectAdmin"
]
}
},
spec.template.spec.containers.args 中的 -b 後參數更改為 $GCS_BUCKET_名稱。spec.template.spec.serviceAccountName 更改為具有 GCS 權限的 K8s Service Account。spec.template.spec.nodeSelector使用上面創建的 2x4 拓撲的 TPU v5e Node Pool。gemma-7b-job.yaml
# gemma-7b-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: data-loader-7b
namespace: ai
spec:
ttlSecondsAfterFinished: 3600 # 1 小時後刪除
template:
spec:
# 填入剛剛創建的 K8s SA 具有 GCS 物件擁有者權限
serviceAccountName: $K8s_Service_Account
restartPolicy: Never
containers:
- name: inference-checkpoint
image: us-docker.pkg.dev/cloud-tpu-images/inference/inference-checkpoint:v0.2.2
args:
- -b=$GCS_BUCKET_Name
- -m=google/gemma/maxtext/7b-it/2
volumeMounts:
- mountPath: "/kaggle/"
name: kaggle-credentials
readOnly: true
resources:
requests:
google.com/tpu: 8
limits:
google.com/tpu: 8
nodeSelector:
cloud.google.com/gke-tpu-topology: 2x4
cloud.google.com/gke-tpu-accelerator: tpu-v5-lite-podslice
# 掛載 kaggle-secret
volumes:
- name: kaggle-credentials
secret:
defaultMode: 0400
secretName: kaggle-secret
大約經過七分鐘後可以訓練完成,使用指令確認 Job Logs,kubectl logs $Job_PodName -n ai。
$ kubectl logs $Job_PodName -n ai
## ...以上省略...
saved an decode checkpoint at gs://$GCS_BUCKET_Name/final/unscanned/gemma_7b-it/0/checkpoints/
Successfully generated decode checkpoint at: gs://$GCS_BUCKET_Name/final/unscanned/gemma_7b-it/0/checkpoints/0/items
Completed unscanning checkpoint to gs://$GCS_BUCKET_Name/final/unscanned/gemma_7b-it/0/checkpoints/0/items
我們將部署 JetStream 容器來應用 Gemma 模型,使用以下指令創建 jetstream-gemma-deployment.yaml 及 Service-Ingress.yaml 檔案
$ kubectl apply -f jetstream-gemma-deployment.yaml
$ kubectl apply -f service-ingress.yaml
jetstream-gemma-deployment.yaml 中的 args 這些參數用於配置maxengine-server:
model_name=gemma-7b: 指定要使用的模型名稱為 Gemma 7B,擁有 70 億個參數,讀者也可以將此改為使用 20 億個參數的 Gemma gemma-2b。per_device_batch_size=4: 設定每個設備(例如:TPU 核心)的批量大小為 4。這意味著每個設備會同時處理 4 個輸入序列。max_prefill_predict_length=1024: 設定預填充(prefill)階段的最大預測長度為 1024 個 token。預填充通常指模型在生成文本的初始階段,使用已知的上下文信息來生成一部分文本。max_target_length=2048: 設定目標序列的最大長度為 2048 個 token。這限制了模型生成文本的最大長度。async_checkpointing=false: 不使用異步檢查點。ici_tensor_parallelism=1: 設定張量並行度為 1。張量並行是一種用於訓練大型模型的並行化技術,它將模型的參數分佈到多個設備上。weight_dtype=bfloat16: 設定模型權重的數據類型為 bfloat16。bfloat16 是一種 16 位浮點數格式,可以提高訓練速度並減少內存使用。load_parameters_path=gs://$GCS_Bucket_Name/final/unscanned/gemma_7b-it/0/checkpoints/0/items: 指定模型參數的加載路徑。這裡的路徑指向 Google Cloud Storage (GCS) 上的一個位置。讀者可以根據需求修改以上的參數。
# jetstream-gemma-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: maxengine-server
namespace: ai
spec:
replicas: 1
selector:
matchLabels:
app: maxengine-server
template:
metadata:
labels:
app: maxengine-server
spec:
# 填入剛剛創建的 K8s SA 具有 GCS 物件擁有者權限
serviceAccountName: $K8s_Service_Account
nodeSelector:
cloud.google.com/gke-tpu-topology: 2x4
cloud.google.com/gke-tpu-accelerator: tpu-v5-lite-podslice
containers:
- name: maxengine-server
image: us-docker.pkg.dev/cloud-tpu-images/inference/maxengine-server:v0.2.2
args:
- model_name=gemma-7b
- tokenizer_path=assets/tokenizer.gemma
- per_device_batch_size=4
- max_prefill_predict_length=1024
- max_target_length=2048
- async_checkpointing=false
- ici_fsdp_parallelism=1
- ici_autoregressive_parallelism=-1
- ici_tensor_parallelism=1
- scan_layers=false
- weight_dtype=bfloat16
- load_parameters_path=gs://$GCS_Bucket_Name/final/unscanned/gemma_7b-it/0/checkpoints/0/items
ports:
- containerPort: 9000
resources:
requests:
google.com/tpu: 8
limits:
google.com/tpu: 8
- name: jetstream-http
image: us-docker.pkg.dev/cloud-tpu-images/inference/jetstream-http:v0.2.2
ports:
- containerPort: 8000
Service-Ingress.yaml
# Service-Ingress.yaml
apiVersion: v1
kind: Service
metadata:
name: jetstream-svc
namespace: ai
spec:
selector:
app: maxengine-server
ports:
- protocol: TCP
name: jetstream-http
port: 8000
targetPort: 8000
- protocol: TCP
name: jetstream-grpc
port: 9000
targetPort: 9000
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: gemma
namespace: ai
annotations:
cert-manager.io/cluster-issuer: letsencrypt-demo
spec:
ingressClassName: external-nginx
tls:
- hosts:
- gemma.demoit.shop
secretName: gemma-tls
rules:
- host: "gemma.demoit.shop"
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: jetstream-svc
port:
number: 8000
Gradio 是一個 Python 函式庫,可以快速輕鬆地創建用於機器學習模型、API 或任何 Python 函數的使用者介面。僅用幾行程式碼就將你的程式碼轉變成一個互動式的網頁應用程式,讓使用者可以輸入資料(例如文字、圖片、聲音),查看模型的輸出,並分享演示給其他人。
特別適合用於演示機器學習模型,Gradio 的主要優點是它的簡潔性和易用性。不需要了解網頁開發的知識,就可以創建出美觀且功能強大的使用者介面。
apiVersion: apps/v1
kind: Deployment
metadata:
name: gradio
namespace: ai
labels:
app: gradio
spec:
replicas: 1
selector:
matchLabels:
app: gradio
template:
metadata:
labels:
app: gradio
spec:
containers:
- name: gradio
image: us-docker.pkg.dev/google-samples/containers/gke/gradio-app:v1.0.3
resources:
requests:
cpu: "512m"
memory: "512Mi"
limits:
cpu: "1"
memory: "512Mi"
env:
- name: CONTEXT_PATH
value: "/generate"
- name: HOST
# 改成 K8s 內部 Jetstream Service 的 DNS 紀錄
value: "http://jetstream-svc.ai.svc:8000"
- name: LLM_ENGINE
value: "max"
- name: MODEL_ID
value: "gradio-gemma"
- name: USER_PROMPT
value: "<start_of_turn>user\nprompt<end_of_turn>\n"
- name: SYSTEM_PROMPT
value: "<start_of_turn>model\nprompt<end_of_turn>\n"
ports:
- containerPort: 7860
---
apiVersion: v1
kind: Service
metadata:
name: gradio
namespace: ai
spec:
selector:
app: gradio
ports:
- protocol: TCP
port: 7860
targetPort: 7860
type: ClusterIP
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: gradio-gemma
namespace: ai
annotations:
cert-manager.io/cluster-issuer: letsencrypt-demo
spec:
ingressClassName: external-nginx
tls:
- hosts:
- gradio-gemma.demoit.shop
secretName: gradio-gemma-tls
rules:
- host: "gradio-gemma.demoit.shop"
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: gradio
port:
number: 7860
等待部署完成後,進入網頁,可以看到輸入 Prompt 的欄位,
本文詳細介紹了如何在GKE上部署Gemma 7B模型,並利用JetStream和Gradio構建一個可用的聊天機器人。
文章從TPU節點池的選擇和創建開始,逐步引導讀者完成模型的訪問授權、數據準備、模型轉換和部署等關鍵步驟。
此外,文章還整合了 Workload Identity 和 GCS 等相關知識,使整個部署流程更加完整和易於理解。
即使本文篇幅較長,讀者只需按步驟操作,即可輕鬆在 GKE 上部署 TPU 節點並運行 Gemma 模型,親身體驗 TPU 的強大效能。

